



Should You Retrain That Model? (Part 1)
Why models rot, why teams postpone, and why “just monitor for drift” fails


Machine-learning models are trained on a fixed slice of history and don’t age like fine wine. The world shifts under their feet. Performance usually decays quietly, and in many organizations it’s not noticed until it’s expensive. Leadership assumes the model “should still work.” Teams put retraining behind net-new projects. What looked like routine maintenance becomes avoidable loss.
At TrueTheta, we spend a lot of time helping companies sharpen and modernize their machine-learning models. Last month, we were invited to present to Lyft’s machine-learning team on one deceptively simple question: When should a company retrain its internal models? It’s a question that’s getting more urgent as more and more organizations deploy AI in core operations. The talk sparked a lot of feedback and follow-up conversations, so we decided to turn it into a three part series here.
This first post is about the problem. We’ll talk about the incentives that delay retraining, explain why the well-intentioned “monitor for drift and retrain on a threshold” playbook isn’t a policy. In Parts 2 and 3, we’ll cover the fix - reframing when to retrain into an engineering and operations question you can actually win, and the best practices that make retraining boring, fast, and safe.
If you’re leading a machine-learning team - or you’re at a company that could benefit from this presentation - get in touch. We’re always happy to bring this conversation into the room.
Why retraining is undervalued

The case for retraining is boring and decisive: if your data distribution and labeling environment are moving, a model trained on last year’s reality becomes less relevant. Because observability is hard, degradation is often silent. Retraining on fresher data is the straightest path to claw back performance.
So why doesn’t it happen on time? First, the human cost is real. Original builders leave, and the knowledge encoded in their choices leaks away. Reconstructing “why that feature, why that threshold, why that filter” is slow. Meanwhile, infra drifts too - versions, schemas, batch jobs, orchestration. Second, scope creep turns a week of hygiene into a quarter of pain. “If we’re retraining anyway, let’s add features, migrate storage, clean up pipelines, fix monitoring…” Suddenly no one wants to green-light it. Third, the incentives are misaligned. Retraining isn’t “new science,” so ICs don’t get excited; leaders frame it as obligation rather than opportunity. The result is a slow-motion yes that functions like a no.
Two failures to remember
Zillow Offers (2021): stale signals, expensive lessons. The iBuying program leaned on pricing models calibrated to a regime of rising home prices and cheap carrying costs. When the market cooled, those models kept overpaying. The reckoning came as a nine-figure write-down, a program shutdown, and thousands of layoffs - an object lesson in what happens when you don’t adapt models to updated realities quickly enough.
Pandemic-era relief fraud (2020–2022): adversaries iterate faster. PPP/EIDL firehosed capital into the economy and drew a new class of attacker. Tactics evolved - automation, synthetic identities, collusive rings - while many legacy rules and models stood still. Ground truth lagged by days or weeks, giving fraud a head start. The result was losses large enough to trigger emergency mandates for real-time detection. Stale models weren’t just underperforming; they were liabilities.
A shared language: data drift vs. concept drift
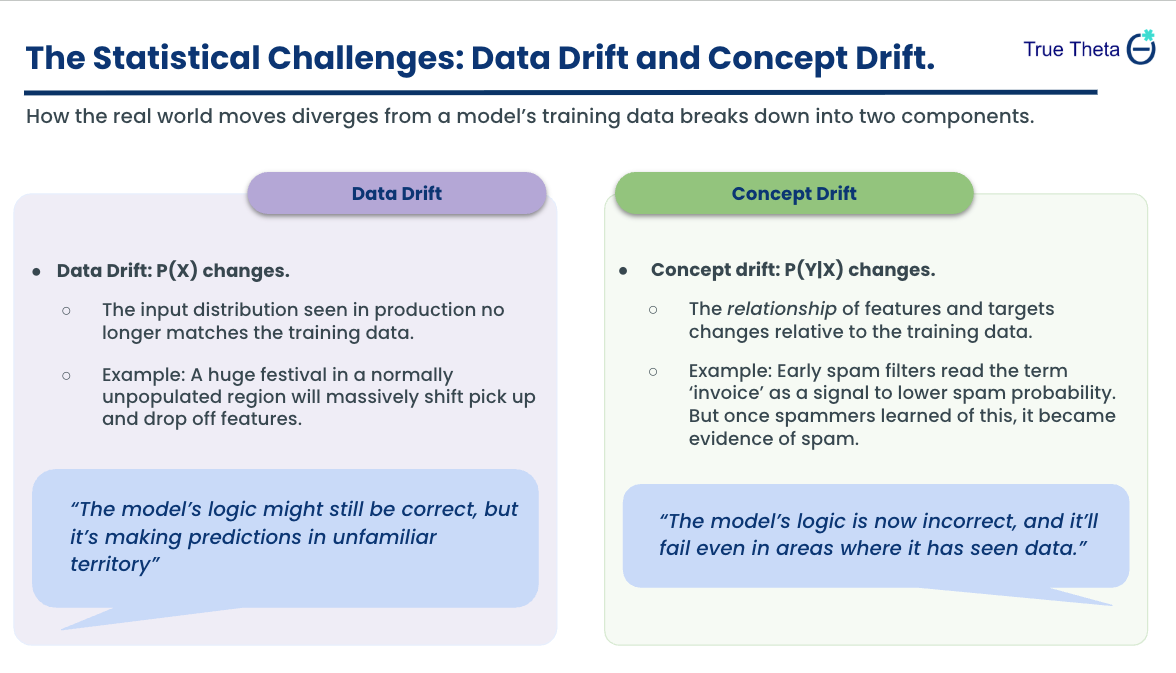
Teams often conflate two different failures. Data drift means the inputs change: the distribution P(X) shifts so the model spends more time in parts of feature space it barely saw during training. Picture a rideshare network where a regional event suddenly floods the system with trips from a previously sparse area. Even a “correct” model will struggle out of distribution.
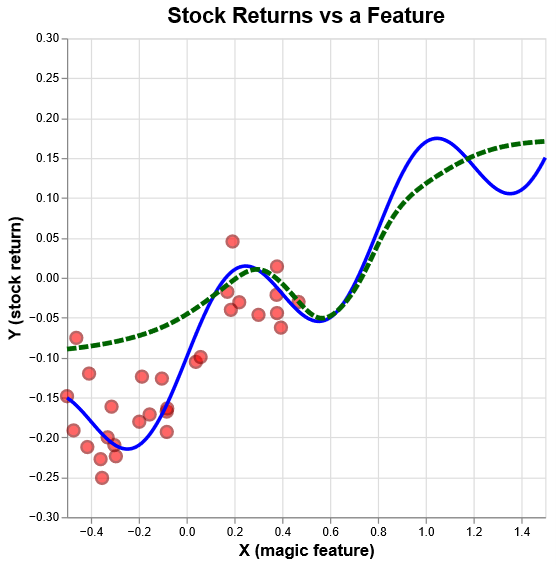
Concept drift happens when the rules of the game change, the relationship between inputs and outputs shifts, even if the inputs themselves look the same. Illustration helps. If the data shifts, your error spikes in unfamiliar regions - that’s data drift. If the curve itself bends while your estimate stays put, you’re wrong even in regions you used to own - that’s concept drift. And because models drive policies - how much inventory to buy, what credit to extend, which claims to audit - errors don’t just show up on dashboards. They show up as bad decisions.
Why “just monitor for drift” isn’t a policy
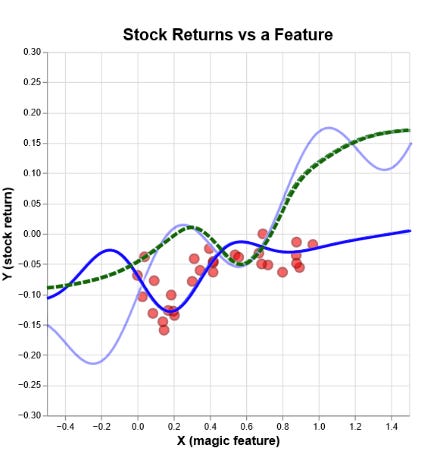
The standard playbook sounds sensible: test for input drift on key features, watch the prediction distribution for big swings, track errors and retrain when metrics deteriorate. In practice, it disappoints.
Start with hypothesis overload. In a feature set with hundreds of fields, honest noise will trip p-value alarms somewhere nearly every day. You’ll either retrain constantly or ratchet thresholds until nothing fires. There’s no stable middle. Then there’s what we call the “one-dimensional trap.” Your model takes in many features, but you might only be watching the overall distribution of its predictions. If some features change in a way that pushes predictions up and others change in a way that pushes them down, those effects can cancel out. The prediction curve will look stable, even though the inputs feeding the model have shifted a lot underneath.Most importantly, error monitoring is lagging by definition. In domains like credit and fraud, the labels that matter arrive hours or days later. By the time your “stat sig” alarm goes off, you’ve already paid the tuition. All of this assumes your monitoring is measuring the right thing; in many stacks it isn’t, and the model fails silently.
Monitoring is necessary. It isn’t sufficient. At best it produces clues. It doesn’t answer the counterfactual you actually care about: Is retraining now better than doing nothing for the next N days? Treating that decision as a threshold on a drift metric is how teams end up with expensive surprises.
In Part 2, we’ll take the “Should we retrain?” question and put it under a different lens. Instead of chasing perfect drift thresholds, we’ll treat it as what it really is: a choice between two worlds: keep the incumbent as-is, or refresh it now.
Nice blog post about a classic problem that people are still dealing with today. I really like how "just monitor for drift" is not a solution. More people need to hear this!